在Elasticsearch中,索引分析模块是可以通过注册分词器(analyzer)来进行配置。分词器的作用是当一个文档被索引的时候分词器从文档中提取出若干词元(token)来支持索引的存储和搜索。
Analysis 与Analyzer
- Analysis -文本分析是把全文本转换为一系列索引词(
term)/词元(token)的过程,也叫分词 - Analysis 是通过Analyer 来实现的
- 可使用 Elasticsearch 内置的分析器/ 或者按需定制化分析器
- 除了在数据写入时转换词条,匹配Query语句时候也需要用相同的分析器对查询语句进行分析
Analyzer (分词器)的组成
分词器是专门处理分词的组件,分词器(analyzer)是由字符过滤器(Character Filters)、一个分解器(tokenizer)、零个或多个词元过滤器(token filters)组成。
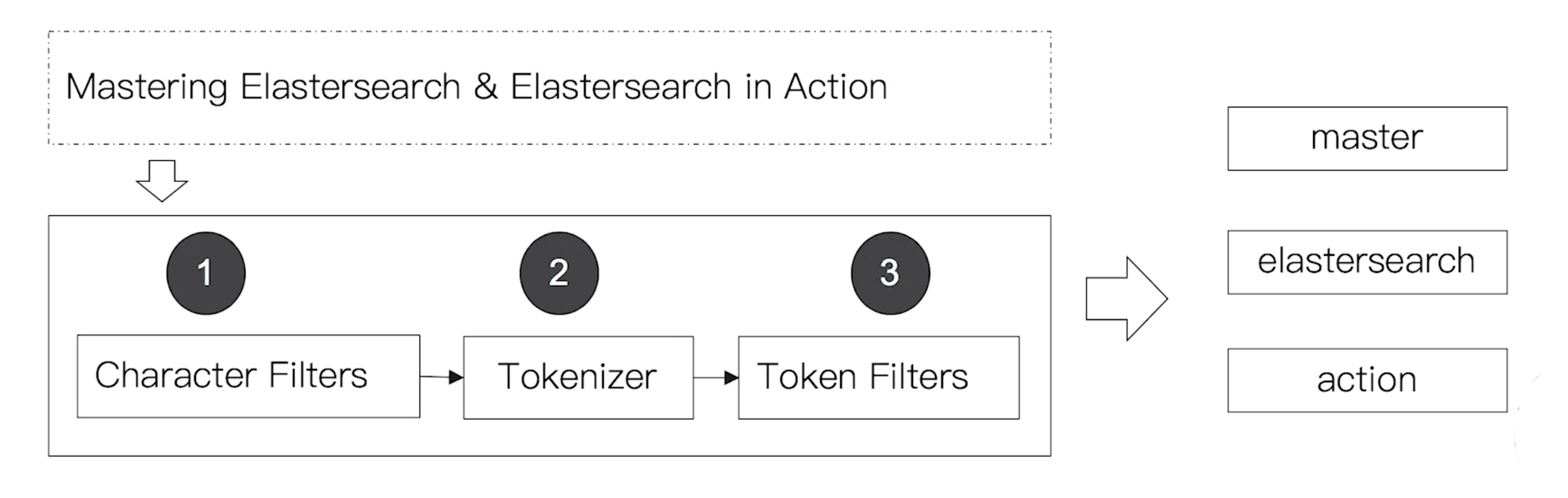
Character Filters (字符过滤器)
在分解器(Tokenizer)之前对文本进行预处理。处理的算法称谓字符过滤器(Character Filters)
一个分解器(Tokenizer)会有一个或多个字符过滤器(Character Filters)。针对原始文本处理。会影响分解器(Tokenizer)的position和offset信息。
Elasticsearch 自带的 Character Filters
- HTML strip - 去除html标签
- Mapping - 字符串替换
- Pattern replace - 正则匹配替换
例子
将文本中的 中划线[ - ] 替换成 下划线 [ _ ]
GET _analyze
{
"char_filter": [
{
"type":"mapping",
"mappings":["- => _"]
}
],
"text": "123-456"
}
返回结果:
{
"tokens" : [
{
"token" : "123_456",
"start_offset" : 0,
"end_offset" : 8,
"type" : "word",
"position" : 0
}
]
}
替换表情符号
GET _analyze
{
"char_filter": [
{
"type":"mapping",
"mappings":[":) => happy",":( => sad"]
}
],
"text": ["I am felling :)","Feeling :( today"]
}
返回结果:
{
"tokens" : [
{
"token" : "I am felling happy",
"start_offset" : 0,
"end_offset" : 15,
"type" : "word",
"position" : 0
},
{
"token" : "Feeling sad today",
"start_offset" : 16,
"end_offset" : 32,
"type" : "word",
"position" : 1
}
]
}
正则表达式
GET _analyze
{
"char_filter": [
{
"type":"pattern_replace",
"pattern":"http://(.*)",
"replacement":"$1"
}
],
"text": "http://www.elastic.co"
}
返回结果:
{
"tokens" : [
{
"token" : "www.elastic.co",
"start_offset" : 0,
"end_offset" : 21,
"type" : "word",
"position" : 0
}
]
}
tokenizer(分解器)
按照规则切分为单词,把字符串分解成一系列词元。
一个简单的分解器是把一个橘子当遇到空格或标点符号时,分解成一个个的索引词。
Elasticsearch 内置的 Tokenizers
- whitespace
- standard
- uax_url_email
- pattern
- keyword
- path hierarchy 文件路径
可以用 Java 开发插件,实现自己的Tokenizer
例子
path_hierarchy
GET _analyze
{
"tokenizer": "path_hierarchy",
"text": "/usr/local/bin"
}
返回结果:
{
"tokens" : [
{
"token" : "/usr",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 0
},
{
"token" : "/usr/local",
"start_offset" : 0,
"end_offset" : 10,
"type" : "word",
"position" : 0
},
{
"token" : "/usr/local/bin",
"start_offset" : 0,
"end_offset" : 14,
"type" : "word",
"position" : 0
}
]
}
token filters (词元过滤器)
对分词器提取出来的单词、词元做进一步的处理。
将切分的单词进行加工,例如:小写,删除 stopwords,增加同义词
Elasticsearch 自带的token filters
- lowercase (小写处理)
- stop (删除修饰性词语)
- synonym(添加近义词)
例子
stop
不能只使用 filter,所以我们用都使用whitespace tokenizer 来做个对比
- 不使用 stop filter
GET _analyze
{
"tokenizer": "whitespace",
"text": "The rain in Spain falls mainly on the plain."
}
返回结果:
{
"tokens" : [
{
"token" : "The",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "rain",
"start_offset" : 4,
"end_offset" : 8,
"type" : "word",
"position" : 1
},
{
"token" : "in",
"start_offset" : 9,
"end_offset" : 11,
"type" : "word",
"position" : 2
},
{
"token" : "Spain",
"start_offset" : 12,
"end_offset" : 17,
"type" : "word",
"position" : 3
},
{
"token" : "falls",
"start_offset" : 18,
"end_offset" : 23,
"type" : "word",
"position" : 4
},
{
"token" : "mainly",
"start_offset" : 24,
"end_offset" : 30,
"type" : "word",
"position" : 5
},
{
"token" : "on",
"start_offset" : 31,
"end_offset" : 33,
"type" : "word",
"position" : 6
},
{
"token" : "the",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 7
},
{
"token" : "plain.",
"start_offset" : 38,
"end_offset" : 44,
"type" : "word",
"position" : 8
}
]
}
- 使用 stop filter
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop"],
"text": "The rain in Spain falls mainly on the plain."
}
返回结果:
{
"tokens" : [
{
"token" : "The",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "rain",
"start_offset" : 4,
"end_offset" : 8,
"type" : "word",
"position" : 1
},
{
"token" : "Spain",
"start_offset" : 12,
"end_offset" : 17,
"type" : "word",
"position" : 3
},
{
"token" : "falls",
"start_offset" : 18,
"end_offset" : 23,
"type" : "word",
"position" : 4
},
{
"token" : "mainly",
"start_offset" : 24,
"end_offset" : 30,
"type" : "word",
"position" : 5
},
{
"token" : "plain.",
"start_offset" : 38,
"end_offset" : 44,
"type" : "word",
"position" : 8
}
]
}
使用 _analyzer API
直接指定Analyzer 进行测试
GET /_analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
指定索引的字段进行测试
POST books/_analyze
{
"field": "title",
"text": "Mastering Elasticsearch"
}
自定义分词器进行测试
POST /_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "Mastering Elasticsearch"
}
Elasticsearch的内置分词器
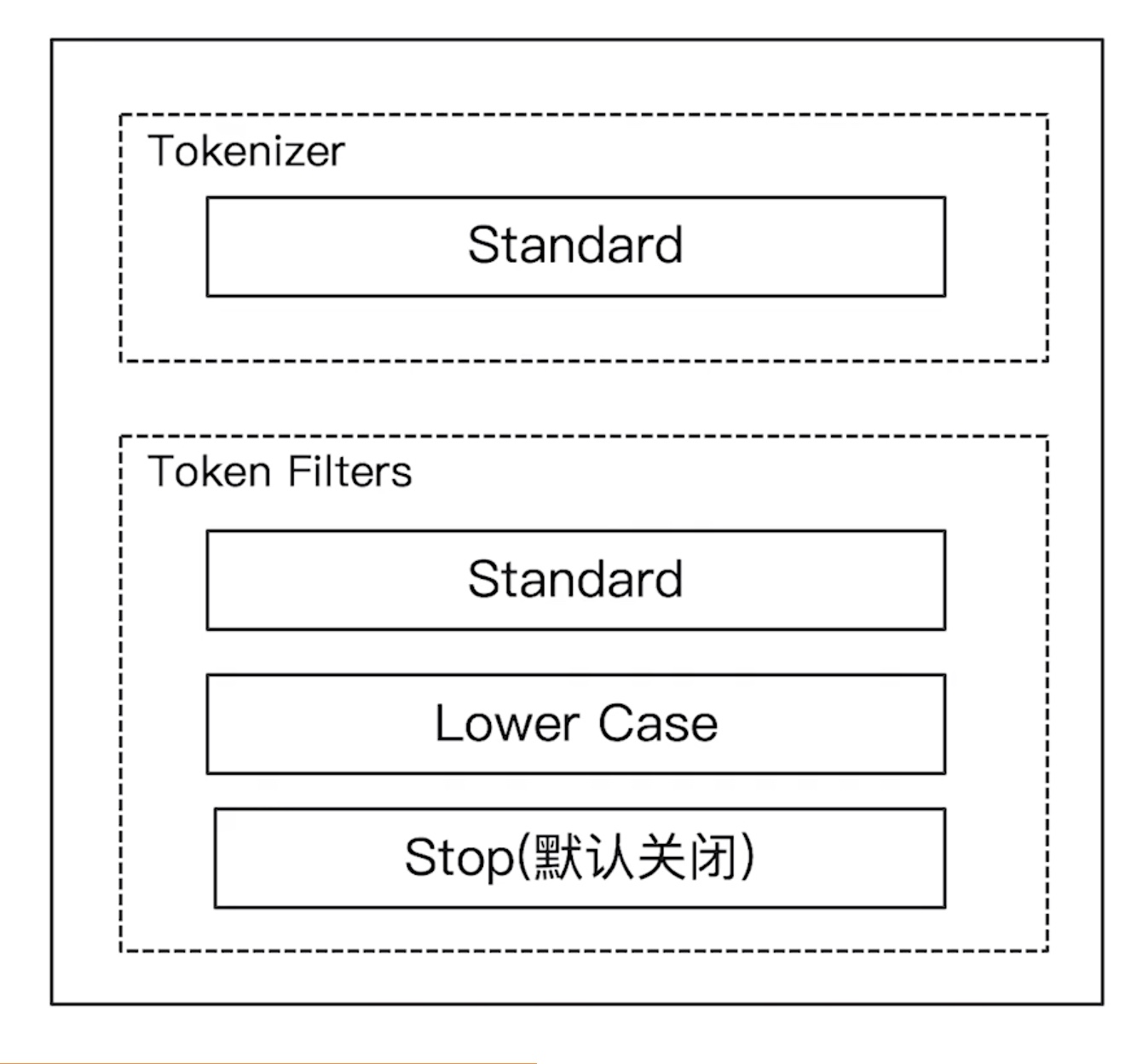
Standard Analyzer
- elasticsearch 默认的分词器
- 按词切分
- 小写处理
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
返回结果:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "<ALPHANUM>",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "<ALPHANUM>",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "<ALPHANUM>",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "<ALPHANUM>",
"position" : 12
}
]
}
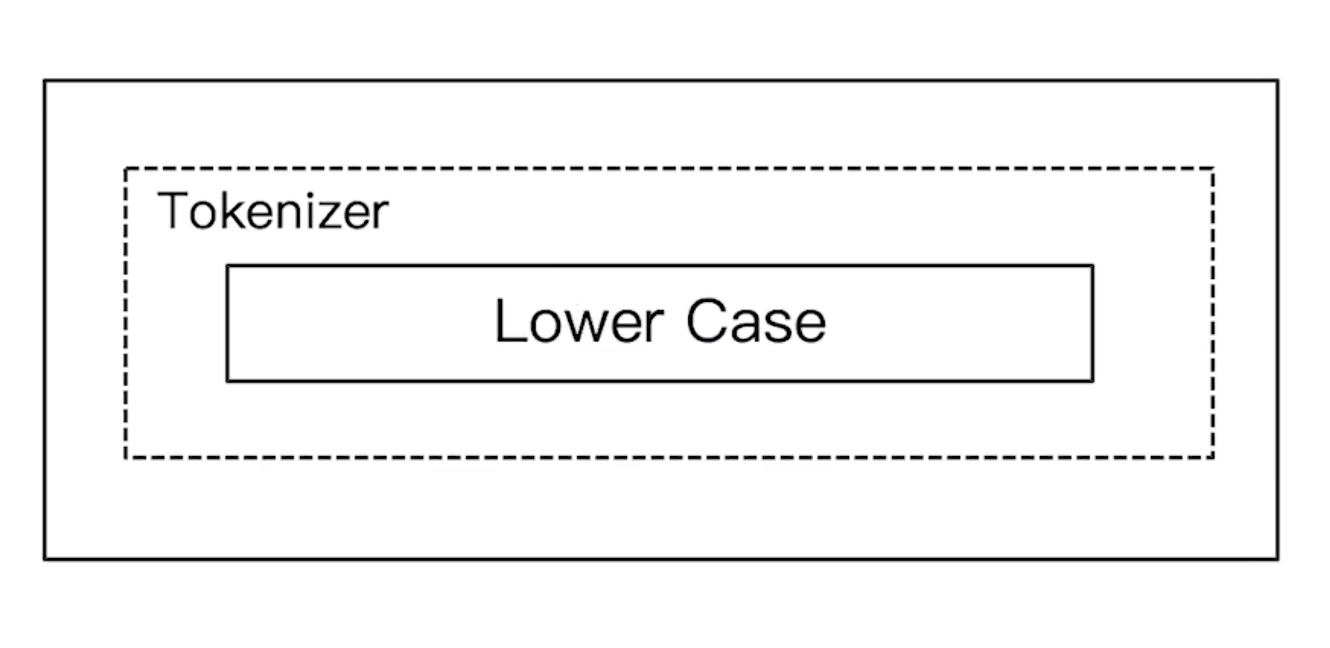
Simple Analyzer
- 按照非字母切分,非字母对都被去除
- 小写处理
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
返回结果:
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 9
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
Whitespace Analyzer
- 按照空格切分

GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
返回结果:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "Quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown-foxes",
"start_offset" : 16,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 9
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening.",
"start_offset" : 62,
"end_offset" : 70,
"type" : "word",
"position" : 11
}
]
}
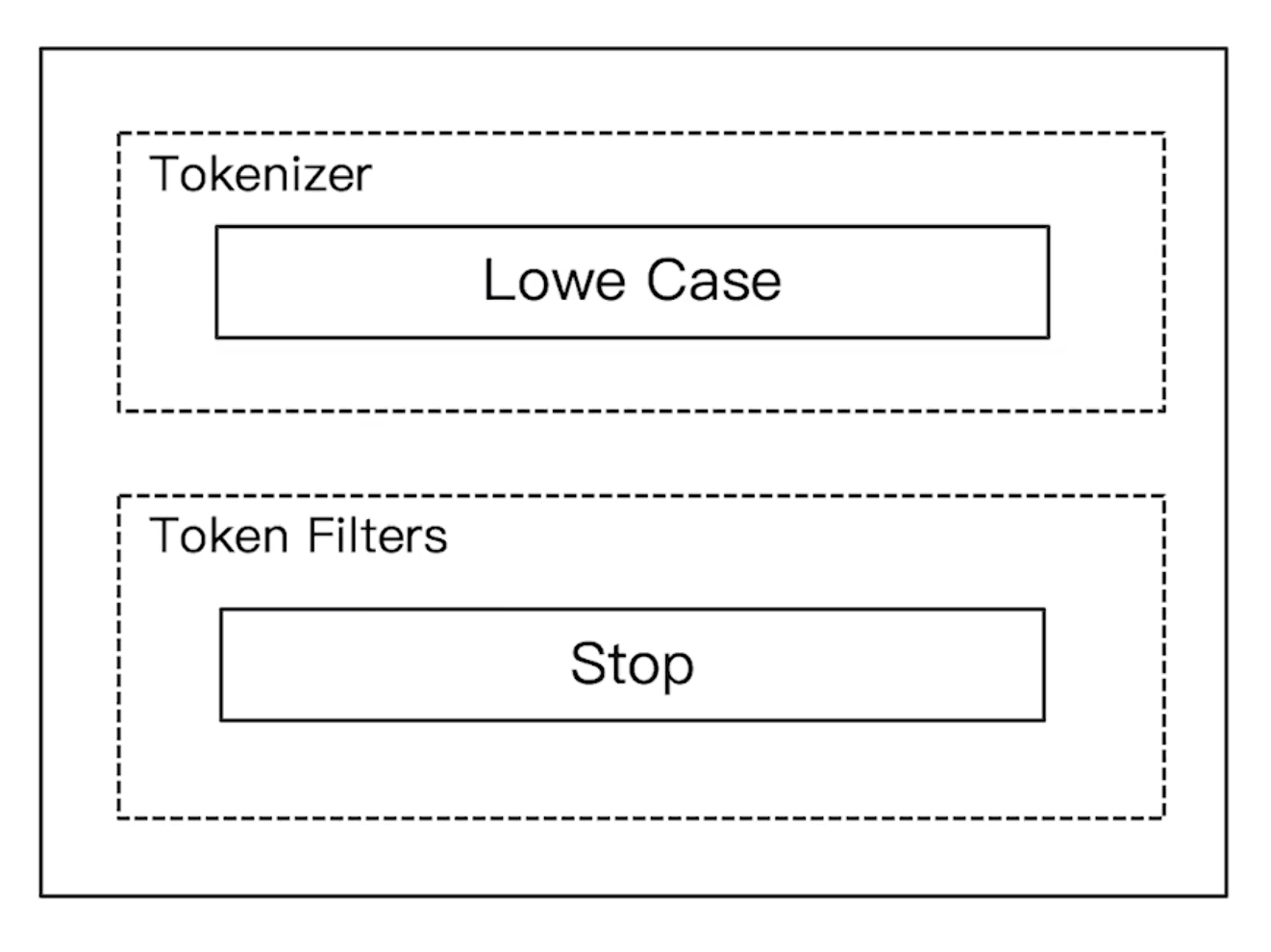
Stop Analyzer
- 相比 Simple Analyzer 多了stop filter
- 会把
the,a,is等修饰性词语去除
- 会把
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
返回结果:
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
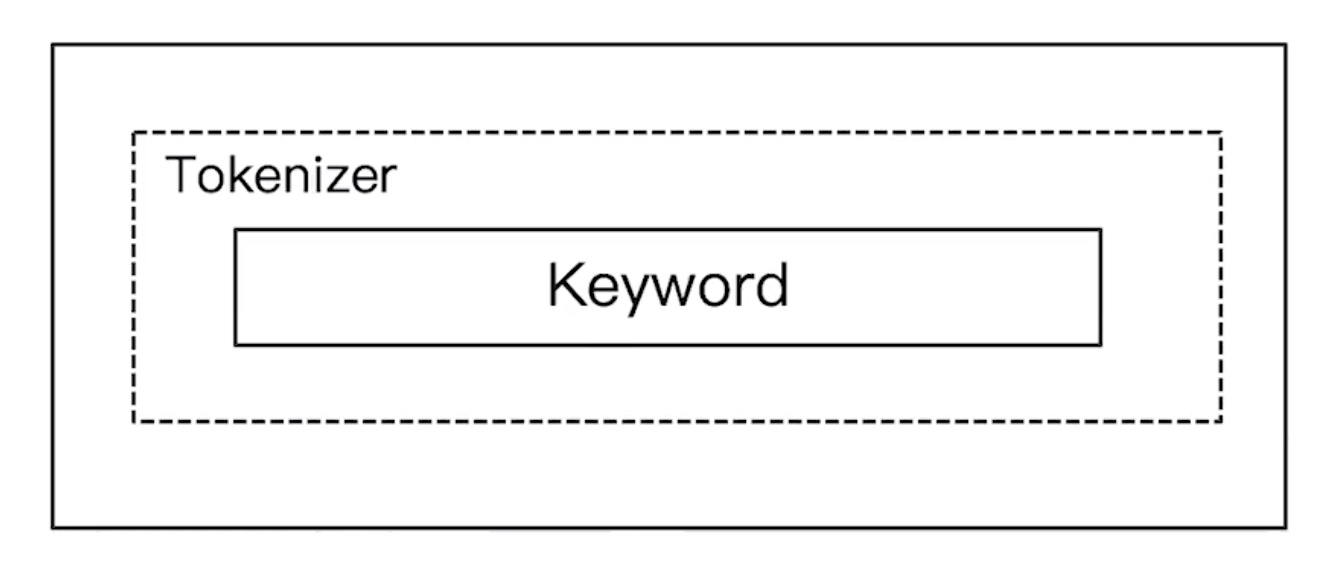
Keyword Analyzer
- 不分词,直接将输入当一个
term输出
GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
返回结果:
{
"tokens" : [
{
"token" : "2 running Quick brown-foxes leap over lazy dogs in the summer evening.",
"start_offset" : 0,
"end_offset" : 70,
"type" : "word",
"position" : 0
}
]
}
没有做任何的处理,直接把结果按一个term输出了
Pattern Analyzer
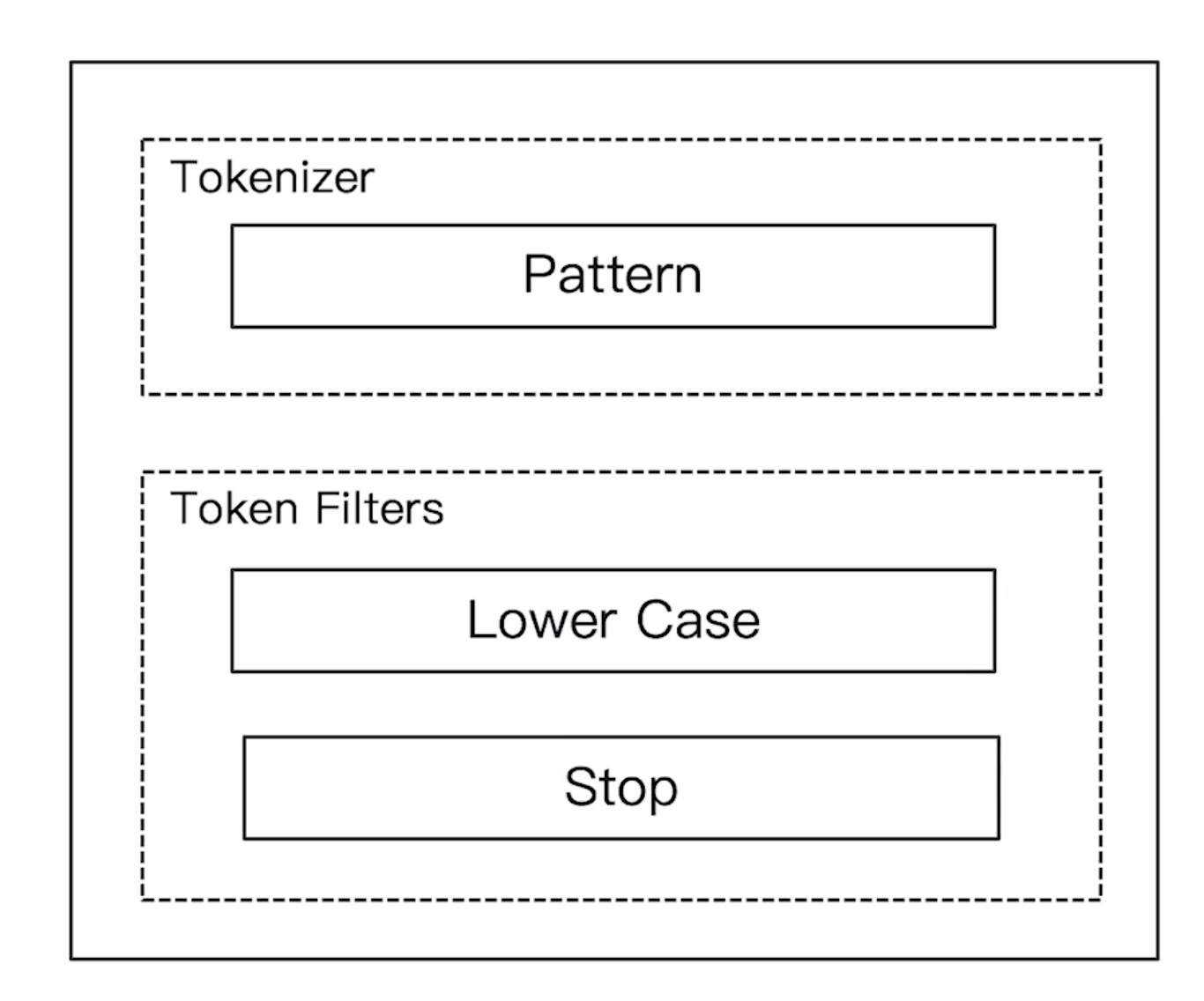
- 通过正则表达式进行分词
- 默认是\W+,非字符的符号进行分隔
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
返回结果:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 7
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 12
}
]
}
Language - 提供了30多种常见语言的分词器
针对不同的语言. 支持以下类型:
- arabic
- armenian
- basque
- bengali
- brazilian
- bulgarian
- catalan
- cjk
- czech
- danish
- dutch
- english
- finnish
- french
- galician
- german
- greek
- hindi
- hungarian
- indonesian
- irish
- italian
- latvian
- lithuanian
- norwegian
- persian
- portuguese
- romanian
- russian
- sorani
- spanish
- swedish
- turkish
- thai
自定义分词器
自定义分析器标准格式:
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": { ... custom character filters ... },//字符过滤器
"tokenizer": { ... custom tokenizers ... },//分词器
"filter": { ... custom token filters ... }, //词单元过滤器
"analyzer": { ... custom analyzers ... }
}
}
}
my_custom_analyzer
在一个索引(test_custom_analyzer)上定义一个自定义的分词器(my_custom_analyzer)。分词器使用的自定义的字符过滤器(emoticons)、自定义的分解器(punctuation)、自定义的词元过滤器(english_stop)和系统内置的(lowercase)。
定义分词器
PUT test_custom_analyzer
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{
"type":"custom",
"char_filter":[
"emoticons"
],
"tokenizer":"punctuation",
"filter":[
"lowercase",
"english_stop"
]
}
},
"tokenizer": {
"punctuation":{
"type":"pattern",
"pattern":"[ .,!?]"
}
},
"char_filter": {
"emoticons":{
"type":"mapping",
"mappings":[":) => _happy_",":( => _sad_"]
}
},
"filter": {
"english_stop":{
"type":"stop",
"stopwords":"_english_"
}
}
}
}
}
测试自定义的分词器
POST test_custom_analyzer/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "I'm a :) person, and you? "
}
解析
PUT test_custom_analyzer # 在一个索引上定义一个分词器
{
"settings": {
"analysis": {
"analyzer": { # 自定义分词器
"my_custom_analyzer":{ # 分词器名字
"type":"custom",
"char_filter":[ # 分词器所需要使用的 字符过滤器
"emoticons" # 字符过滤器的名字,这个是自定义的,在char_filter 里可以看到定义
],
"tokenizer":"punctuation", # 分词器所需要使用的 分解器
"filter":[ # 分解器所调用的 词元过滤器
"lowercase",
"english_stop" # 词元过滤器 这个是自定义的 在filter里可以看到定义
]
}
},
"tokenizer": { # 自定义 分解器
"punctuation":{ # 分解器的名字
"type":"pattern",
"pattern":"[ .,!?]"
}
},
"char_filter": { #自定义字符过滤器
"emoticons":{ # 字符过滤器的名字
"type":"mapping",
"mappings":[":) => _happy_",":( => _sad_"]
}
},
"filter": { # 自定义 词元过滤器
"english_stop":{ # 词元过滤器的名字
"type":"stop",
"stopwords":"_english_"
}
}
}
}
}
其他分词器
Analysis-ICU
提供了Unicode的支持,更好的支持亚洲语言
- https://github.com/elastic/elasticsearch-analysis-icu
安装
# 需要找到你的elasticsearch-plugin命令所在位置
sudo /you-path/elasticsearch-plugin install analysis-icu
Analysis-IK (中文分词插件)
支持自定义词库,支持热更新分词字典
- https://github.com/medcl/elasticsearch-analysis-ik
安装
# 需要找到你的elasticsearch-plugin命令所在位置
sudo /you-path/elasticsearch-plugin list
analysis-ik
HanLP (中文分词插件)
面向生产环境的自然语言处理工具
- http://hanlp.com/
- https://github.com/KennFalcon/elasticsearch-analysis-hanlp
安装
# 需要找到你的elasticsearch-plugin命令所在位置
sudo /you-path/elasticsearch-plugin install https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v7.2.0/elasticsearch-analysis-hanlp-7.2.0.zip
Pinyin (拼音)
- https://github.com/medcl/elasticsearch-analysis-pinyin
安装
# 需要找到你的elasticsearch-plugin命令所在位置
sudo /you-path/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.2.0/elasticsearch-analysis-pinyin-7.2.0.zip