Elasticsearch 是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。现在是使用最广的开源搜索引擎之一,Wikipedia、Stack Overflow、GitHub 等都基于 Elasticsearch 来构建他们的搜索引擎。
基础知识
索引词(term)
在Elasticsearch 中 索引词(term)是一个能够被索引的精确值。
foo、Foo、FOO几个单词是不同的索引词。索引词(term)是可以通过term查询进行准确的搜索。
文本(text)
文本是一段普通的非结构化的文字。通常,文本会被分析成一个个的索引词,存储在Elasticsearch 的索引库中。为了让文本能够进行搜索,文本字段需要实现进行分析;当对文本中的关键词进行查询的时候,搜索引擎应该根据搜索条件搜索出原文本
分析(analysis)
分析是将文本转化为索引词的过程,分析的结果依赖于分词器。比如FOO BAR、Foo-Bar 和 foo bar 这几个单词有可能会被分析称相同的索引词foo和bar,这些索引词存储在Elasticsearch的索引库中。当用FoO:bAR 进行全文搜索的时候,搜索引擎根据匹配计算也能在索引库中搜索出之前的内容。这就是Elasticsearch的搜索分析
集群(cluster)
集群由一个或多个节点组成,对外提供服务,对外提供索引和搜索功能。
- 在所有节点,一个集群有一个唯一的名称默认为
Elasticsearch。 - 因为每个节点只能是集群的一部分,当该节点被设置为相同的集群名称时,就会自动加入集群。
- 当需要有多个集群的时候,要确保每个集群的名称不能重复,否则,节点可能加入错误的集群。
请注意,一个节点只能加入一个集群。此外,你还可以拥有多个独立的集群,每个集群都有起不同的集群名称。例如,在开发过程中,你可以建立开发集群库和测试集群库,分别为开发、测试服务。
Elasticsearch集群结构
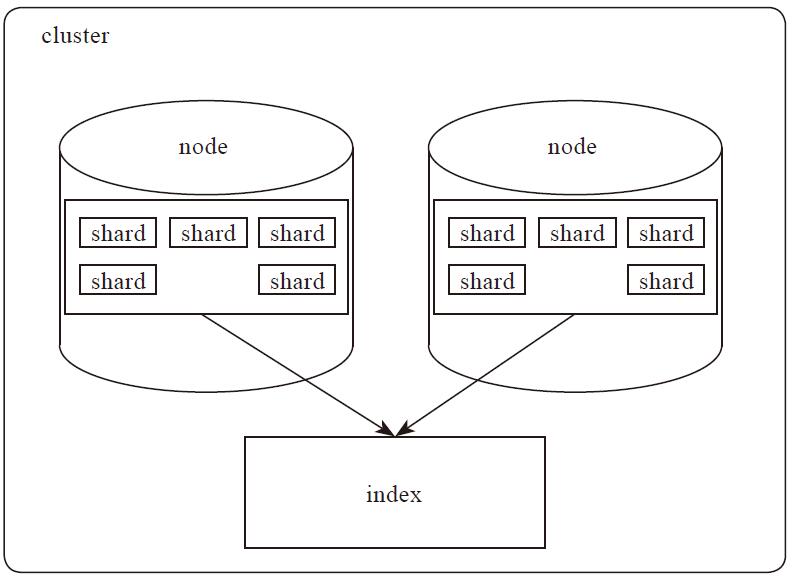
节点(node)
一个节点是一个逻辑上独立的服务,他是集群的一部分,可以存储数据,并参与集群的索引和搜索功能。
- 节点是一个
Elasticsearch的实例- 本质上就是一个java进程
- 一台机器上可以运行多个
Elasticsearch进程,但是生产环境一般建议一台机器上只运行一个Elasticsearch实例
- 每一个节点都有名字,通过配置文件配置,或者启动的时候 -E node.name=node1 指定
- 每一个节点在启动之后,会分配一个UID,保存在data目录下
Master-eligible nodes 和 MasterNode
- 每个节点启动后,默认就是一个Master eligible节点
- 可以设置 node.master:false 禁止
- Master-eligible 节点可以参加选主流程,成为Master节点
- 当第一个节点启动当时候,他会将自己选举为Master节点
- 每个节点上都保存了集群都状态人,只有Master节点才能修改集群都状态信息
- 集群状态(Cluster State)维护了一个集群中必要的信息
- 所有的节点新
- 所有的索引和其相关的Mapping与Setting 信息
- 分片的路由信息
- 任意节点都能修改信息会导致数据的不一致性,
所以只有Master节点才能修改集群的状态信息
- 集群状态(Cluster State)维护了一个集群中必要的信息
Date Node & Coordinating Node
- Data Node
- 可以保存数据的节点,叫做 Data Node 负责保存分片数据。在数据扩展上起到了至关重要的作用
- Coordinating Node
- 负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了 Coordinating Node 的职责
其他的节点类型
- Hot & Warm Node (冷热节点)
- 不同的硬件配置的Data Node,用来实现 Hot & Warn 架构,降低集群部署的成本
- Machine Learning Node
- 负责跑机器学习的Job,用来做异常检测
- Tribe Node
- (5.3 开始使用Cross Cluster Serarch)Tribe Node 连接到不同的Elasticsearch 集群,并且支持将这些集群当成一个单独的集群处理
配置节点类型
- 开发环境中一个节点可以承担多种角色
- 生产环境中,应该设置单一的角色的节点(dedicated node)
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| maste eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | 无 | 每个节点默认都是coordinating节点设置其他类型全部为false |
| machine learning | node.ml | true(需enable x-pack) |
分片(shard)
主分片(primary shard)
- 一个分片是一个运行的Lucene的实例
- 主分片数在索引创建时指定,后续不允许修改,除非
Reindex
副本分片(replica shard)
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
示例
一个三节点的集群中,blogs索引的分片分布情况
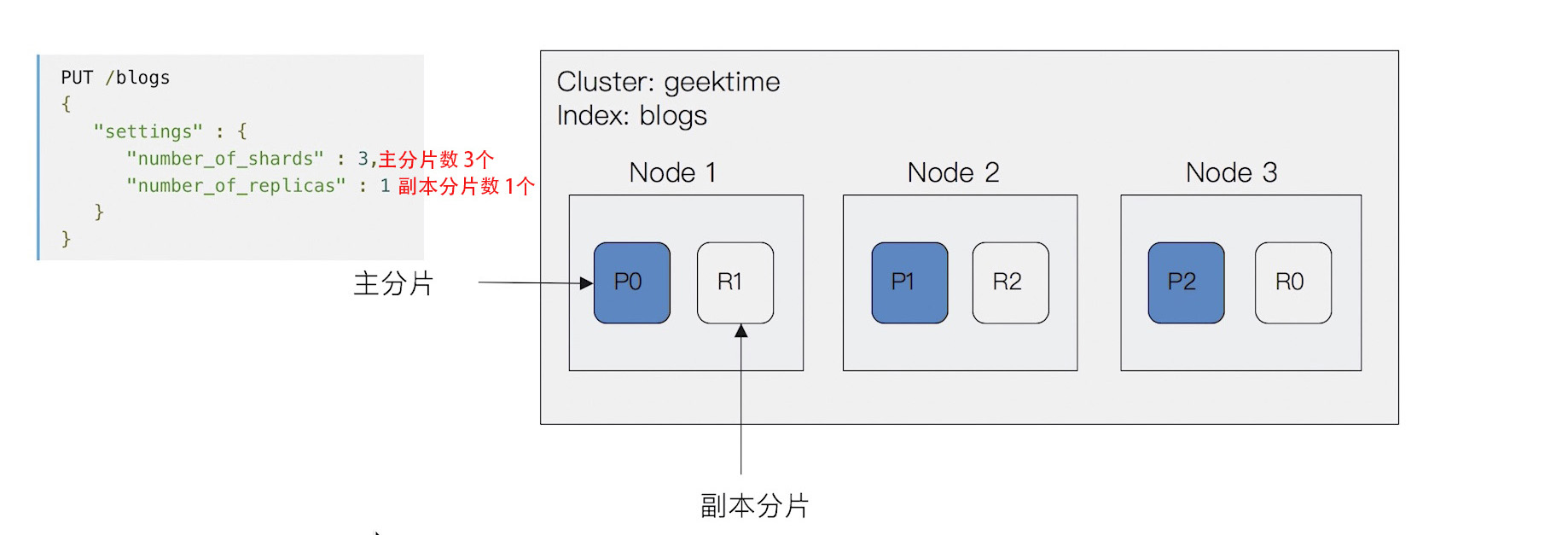
分片的设定
对于生产环境中分片的设定,需要提现做好容量规划
- 分片设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量太大,导致数据重新分配耗时
- 分片设置过大,
7.0之前默认分片数是5个,7.0开始,默认主分片设置成1,解决了over-sharding的问题- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
Demo
在Kibana的开发控制台执行
- 获取集群状态的接口
GET _cluster/health
返回结果:
{
"cluster_name" : "elasticsearch",
"status" : "yellow", //状态是黄色的
"timed_out" : false,
"number_of_nodes" : 1, //只有1个节点
"number_of_data_nodes" : 1,//data node
"active_primary_shards" : 18, //18个主分片
"active_shards" : 18,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 11,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 62.06896551724138
}
- 查看节点信息
GET _cat/nodes
返回结果:
127.0.0.1 28 74 2 0.08 0.20 0.12 mdi * homestead
- 查看分片信息
GET _cat/shards
返回结果:
...
products_2 3 r UNASSIGNED
products_2 0 p STARTED 28 17.3kb 127.0.0.1 homestead
products_2 0 r UNASSIGNED
test_index 2 p STARTED 1 3.5kb 127.0.0.1 homestead
test_index 2 r UNASSIGNED
...
索引(index)
- 索引是具有相同结构的文章集合
- 一个客户信息的索引
- 一个产品目录的索引
- 一个订单数据的索引
- 索引的名字全部小写
- 单个集群中可以定义多个你想要的索引

索引的不同语意

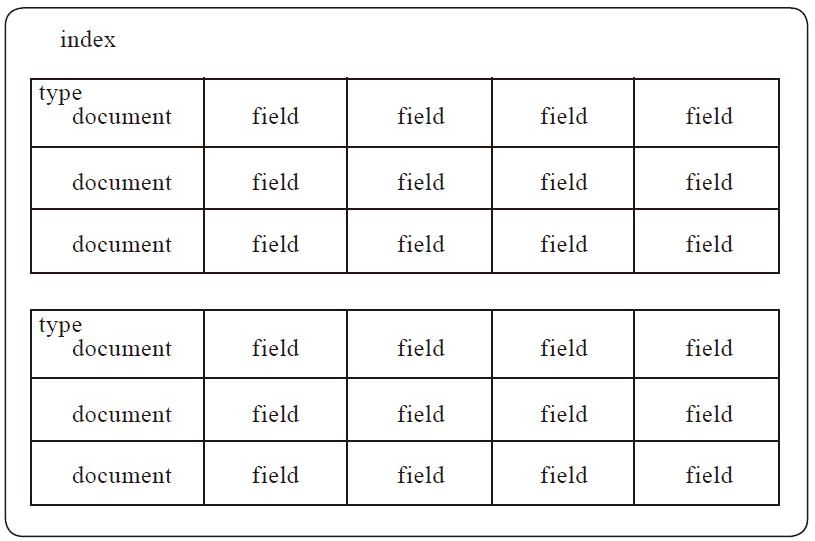
类型 (type)
可以认为是数据库中的一个表
在索引中你可以定义一个或多个类型,类型是索引的逻辑分区。在一般情况下一种类型被定义为具有一组公共字段的文档。例如,让我们假设你运行一个博客平台,并把所有的数据存储在一个索引中。在这个索引中,你可以定义一种类型为用户数据,一种类型为博客数据,另一种类型为评论数据
- 6.0开始Types已经被
Depressed。 - 在7.0之前,一个
index可以设置多个Types - 7.0开始 一个索引只能创建一个Type - “
_doc”
| type | |||
|---|---|---|---|
| document(文档) | field(字段) | field(字段) | field(字段) |
| document(文档) | field(字段) | field(字段) | field(字段) |
| document(文档) | field(字段) | field(字段) | field(字段) |
文档(document)
可以认为是数据库中的一条记录
文档是存储在Elasticsearch中的一个JSON格式的字符串。它就像在关系数据库中表的一行。每个储存在索引中的一个文档都有一个类型和一个ID,每个文档都是一个JSON对象,存储了零个或者多个字段,或者键值对。原始的JSON文档被存储在一个叫做_source的字段中。当搜索文档的时候默认返回的就是这个字段
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位- 日志文件中的一条日志
- 一本电影的信息 / 一张唱片的详细信息
- MP3播放器里的一首歌 / 一篇PDF文档中的具体内容
- 文档会被序列化成JSON格式,保存在
Elasticsearch中- JSON对象由字段组成
- 每个字段都有对应的字段类型(字符串 / 数值 / 布尔 / 日期 / 二进制 / 范围类型)
- 每个文档都有一个Unique ID
- 你可以自己指定 ID
- 或者由
Elasticsearch自动生成
JSON 文档
- 一篇文档包行列一系列的字段,类似于数据库中的一条数据
- JSON 文档,格式灵活,不需要预先定义格式
- 字段类型可以指定或者是通过
Elasticsearch自动推算(不推荐) - 支持数组 / 支持嵌套
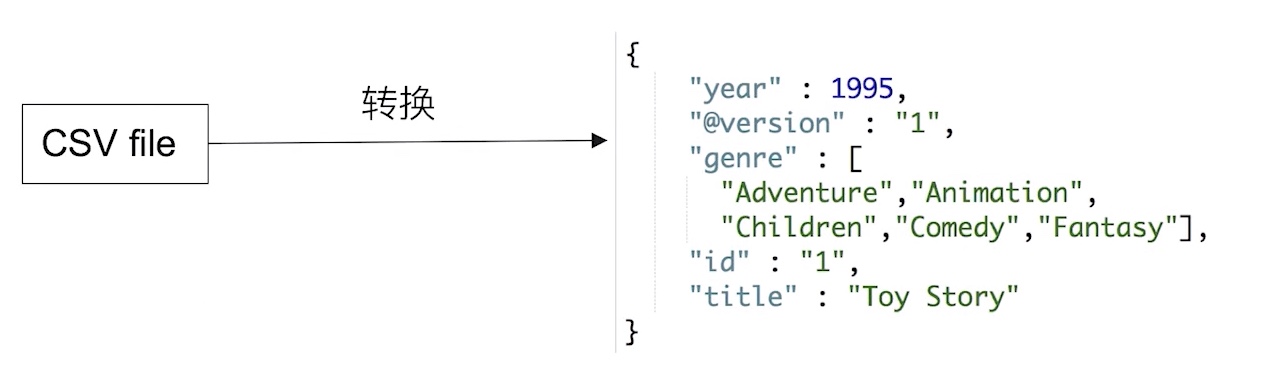
CSV的文件 通过 logstash转化并写入elasticsearch
- 字段类型可以指定或者是通过
文档的元数据

映射(mapping)
可以认为是数据库中的表结构
每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围的设置,一个映射可以事先被定义,或者在第一次存储文档的时候自动识别。
字段(field)
字段类似于关系数据库中表的列
文档中包含零个或者多个字段,字段可以是一个简单的值(例如字符串、整数、日期),也可以是一个数组或队形的嵌套结构。每个字段都对应一个字段类型,例如整数、字符串、对象等。字段还可以指定如何分析该字段等值。
主键(ID)
ID是一个文件的唯一标识。
如果存在库的时候没有提供ID,系统会自动生成一个ID,文档的 id 必须是唯一的。
传统关系型数据库和Elasticsearch的区别
Elasticsearch 本质上是一个数据库,但并不是 Mysql 这种关系型数据库,查询语言也不是 SQL,而且Elasticsearch 自己的一套查询语言。
既然是数据库,有一些概念是互通的,如下表:
| Mysql | Elasticsearch |
|---|---|
| 数据库(Database) | 索引(Index) |
| 表(Table) | 类型(Type) |
| 记录(Row) | 文档(Document) |
| 字段(Column) | 字段(Fields) |